Dieser Artikel ist Teil 2 einer Artikelserie über die Implementierung eines Echtzeit-Finanznachrichten-Agenten. Hier finden Sie den Überblick des Projekts: KI-Fallstudie: Implementierung eines Echtzeit-Finanznachrichten-Agenten - Überblick
Überblick
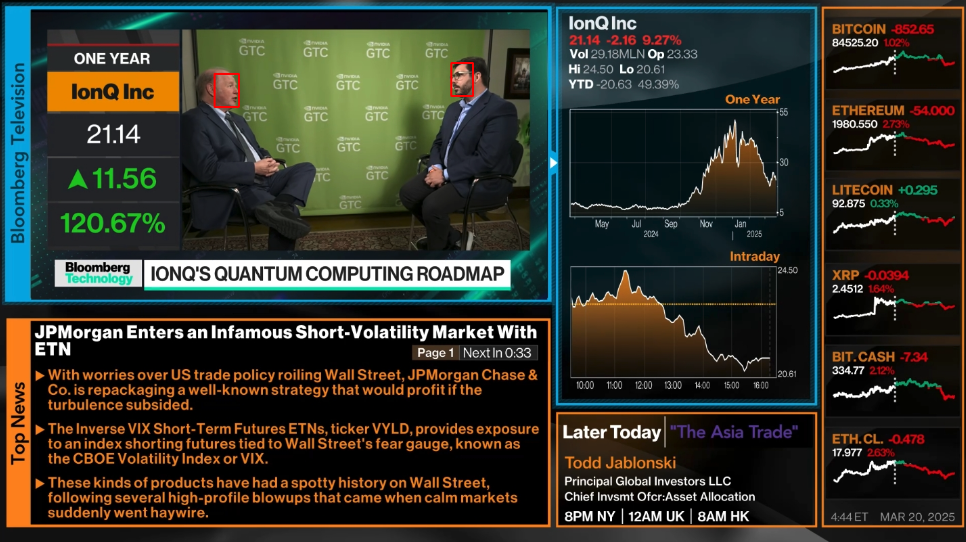
In diesem Teil werden wir den Bildschirm erfassen und die Gesichter der Sprecher extrahieren.
Da wir über Echtzeit-Verarbeitung sprechen, benötigen wir hohe Leistung. Um dies zu erreichen, werden wir den Bildschirm auf einem Client-Rechner erfassen und die Frames an einen leistungsstärkeren Server mit 48 Kernen, 128 GB RAM und 2 Tesla P40 GPUs senden (falls Sie bereits eine GPU auf Ihrem Client-Rechner haben, können Sie Server und Client auf demselben Rechner ausführen). Auf dem Server verarbeiten wir das Video Frame für Frame und erkennen die Gesichter. Für jedes erkannte Gesicht erstellen wir ein Gesichtsembedding. Vorerst geben wir die Embeddings nur auf der Konsole aus. Später werden wir implementieren, dass der Server die Embeddings in einer MongoDB-Datenbank speichert.
- Bildschirmerfassung in einem Client-Server-Modell
- Gesichtserkennung in den Frames (auf dem Server)
- Erstellung von Embeddings der Gesichter (auf dem Server)
Erstellen einer Conda-Umgebung
Um die Abhängigkeiten zu kapseln, verwenden wir eine Conda-Umgebung (Weitere Informationen in der Conda-Dokumentation).
conda create -n ai-news-agent python=3.10
conda activate ai-news-agentCode auschecken (auf Client und Server)
git clone https://github.com/corticalflow/ai-news-agent-part-2.git
cd ai-news-agentAbhängigkeiten installieren
# auf dem Client-Rechner
pip install -r requirements_client.txt
# auf dem Server-Rechner
pip install -r requirements_server.txt
pip install tensorflow[and-cuda]
pip install tf-keras
Datenordner für verarbeitete Frames erstellen
mkdir -p ./dataServer starten (auf dem Server-Rechner)
python server.pyClient starten (auf dem Client-Rechner)
python client.pyClient-Code:
import socket
import cv2
import mss
import numpy as np
import struct
def main():
client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
host_ip = '192.168.100.51' # Replace with server IP address
#host_ip = '127.0.0.1' # Replace with server IP address
port = 9999
client_socket.connect((host_ip, port))
with mss.mss() as sct:
monitor = sct.monitors[3]
try:
while True:
img = np.array(sct.grab(monitor))
frame = cv2.cvtColor(img, cv2.COLOR_BGRA2BGR)
_, buffer = cv2.imencode('.jpg', frame, [cv2.IMWRITE_JPEG_QUALITY, 100])
message = struct.pack(">L", len(buffer)) + buffer.tobytes()
client_socket.sendall(message)
except KeyboardInterrupt:
print("Stopped by user.")
finally:
client_socket.close()
if __name__ == "__main__":
main() Erklärung, was der Code macht:
Der Client-Code ist dafür verantwortlich, den Bildschirm zu erfassen und die Frames für die Echtzeit-Verarbeitung an einen leistungsstarken Server zu streamen. Hier ist, was er tut:
- Socket-Verbindung: Stellt eine TCP-Verbindung zum Server über eine angegebene IP-Adresse und einen Port her.
- Bildschirmerfassung: Verwendet die mss-Bibliothek, um kontinuierlich den Inhalt eines bestimmten Monitors zu erfassen.
- Farbkonvertierung: Konvertiert das erfasste Bild mit OpenCV von BGRA zu BGR und gewährleistet so korrekte Farbgenauigkeit.
- Bildkodierung: Komprimiert jeden Frame in das JPEG-Format (mit 100% Qualität), um ihn für die Netzwerkübertragung zu optimieren.
- Datenverpackung: Verwendet das struct-Modul von Python, um einen Header mit der Länge der JPEG-Daten voranzustellen, damit der Server genau weiß, wie viele Bytes zu lesen sind.
- Frame-Übertragung: Sendet die verpackten Frame-Bytes kontinuierlich über die Socket-Verbindung.
- Ordnungsgemäßes Herunterfahren: Behandelt Tastaturunterbrechungen (KeyboardInterrupt), um die Socket-Verbindung ordnungsgemäß zu schließen, wenn der Benutzer den Prozess stoppt.
Dieses Design stellt sicher, dass der Client effizient Echtzeit-Bilddaten an den Server für weitere Aufgaben wie Gesichtserkennung und Embedding-Generierung streamt.
Server-Code:
import os
# if you dont have an CUDA GPU uncomment the following two lines. The Script will run on CPU which can be slow
#os.environ["CUDA_VISIBLE_DEVICES"] = "-1" # Disable GPU usage to prevent CUDA warnings when drivers are missing.
#os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2" # Suppress TensorFlow info and warning messages.
# we dont have a display so we need to use offscreen rendering
os.environ["QT_QPA_PLATFORM"] = "offscreen" # Use offscreen rendering to bypass display issues
import cv2
import socket
import numpy as np
import struct
from datetime import datetime
from retinaface import RetinaFace # Added import for face detection
from deepface import DeepFace
import tensorflow as tf
print("Num GPUs Available: ", len(tf.config.list_physical_devices('GPU')))
def receive_all(sock, count):
buf = b''
while count:
newbuf = sock.recv(count)
if not newbuf:
return None
buf += newbuf
count -= len(newbuf)
return buf
def main():
print('main')
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
host_ip = '0.0.0.0'
port = 9999
server_socket.bind((host_ip, port))
server_socket.listen(5)
print("Listening at:", (host_ip, port))
client_socket, addr = server_socket.accept()
print('Connection from:', addr)
# Removed GUI window initialization since we're running headless
# cv2.namedWindow('Received', cv2.WINDOW_NORMAL) # No GUI window initialization needed in headless mode
try:
while True:
message_size = receive_all(client_socket, struct.calcsize(">L"))
if not message_size:
break
message_size = struct.unpack(">L", message_size)[0]
frame_data = receive_all(client_socket, message_size)
if not frame_data:
break
print('new frame received')
frame = np.frombuffer(frame_data, dtype=np.uint8)
frame = cv2.imdecode(frame, cv2.IMREAD_COLOR)
# extract text
# Face detection using RetinaFace and drawing bounding boxes
faces = RetinaFace.detect_faces(frame)
if isinstance(faces, dict):
for face in faces.values():
print('found face')
print(face)
bbox = face["facial_area"]
cv2.rectangle(frame, (bbox[0], bbox[1]), (bbox[2], bbox[3]), (0, 0, 255), 2)
# Extract the face region using the bounding box coordinates
face_img = frame[bbox[1]:bbox[3], bbox[0]:bbox[2]]
# Compute vector embedding using DeepFace with the Facenet model
embedding = DeepFace.represent(face_img, model_name='Facenet', enforce_detection=False)
print("Face Embedding:", embedding)
timestamp = datetime.utcnow().timestamp()
# save to filesystem
cv2.imwrite(f'./data/frame_{timestamp}.png', frame)
# Removed GUI key-check as there's no display for capture
# if cv2.waitKey(1) & 0xFF == ord('q'):
# break
except Exception as e:
print(e)
finally:
print('finally')
cv2.destroyAllWindows()
client_socket.close()
server_socket.close()
if __name__ == "__main__":
print("main call")
main() Erklärung, was der Server-Code macht:
- Der Code etabliert eine kontinuierliche Schleife, um Videoframes über eine Netzwerkverbindung zu empfangen.
- Er entpackt die erwartete Größe eines eingehenden Frames und liest die vollständigen Frame-Daten vom Client-Socket.
- Die binären Frame-Daten werden in ein NumPy-Array umgewandelt und dann mit OpenCV in ein Bild dekodiert.
- Es gibt einen Platzhalter für die Textextraktion aus dem Frame (wird später implementiert).
- Die Gesichtserkennung wird mit der RetinaFace-Bibliothek durchgeführt:
- Wenn Gesichter erkannt werden (als Wörterbuch zurückgegeben), iteriert der Code durch jedes Gesicht.
- Für jedes erkannte Gesicht protokolliert er, dass ein Gesicht gefunden wurde, zeichnet einen roten Begrenzungsrahmen um das Gesicht mit den angegebenen Koordinaten und extrahiert den Gesichtsbereich.
- Ein Gesichtsembedding-Vektor wird mit DeepFace unter Verwendung des Facenet-Modells berechnet, und das resultierende Embedding wird protokolliert.
- Ein Zeitstempel wird generiert, und der verarbeitete Frame wird im Dateisystem gespeichert.
- Im finally-Block bereinigt der Code Ressourcen, indem er die OpenCV-Fenster und die Netzwerk-Sockets schließt.
Dieses Design ist für einen Headless-Betrieb optimiert, bei dem keine GUI-Interaktionen (wie Tastendruck-Erkennungen) erforderlich sind.
Weitere Verarbeitung wird beinhalten:
- Speichern der Embeddings in einer MongoDB-Datenbank
- Gesichts-Clustering
- Zuordnung von Identitäten (zum Beispiel von Namensschildern auf dem Bildschirm zu den Gesichtern)
Sie finden den Code für diesen Teil im GitHub-Repository.